Let’s go back to a structure defined in the introductory post:
1 2 3 4 5 | |
If you were testing an application that read a pascal_t, what kind of data would you feed it in an attempt to break it? One strategy might be to throw random data at the program: this is called fuzzing. Because reading string is dependent upon the value of length, it would follow that fuzzing length is more likely to surface vulnerabilities than fuzzing string. This is a classic buffer overflow exploitation.
Binspector knows a lot about a file being analyzed. As it turns out, the knowledge it collects makes this kind of intelligent fuzzing heuristic pretty straightforward to implement.
Consider the following change to the sample binary:
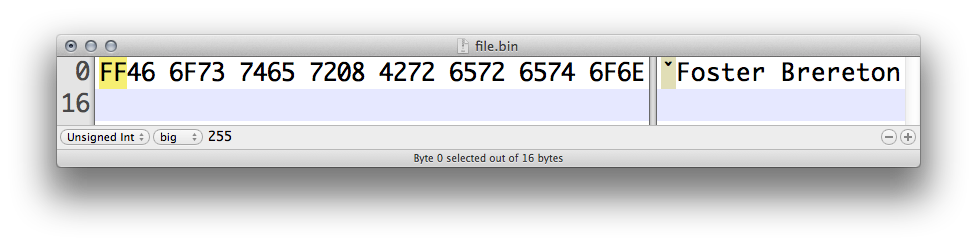
According to the format grammar, the binary file is no longer well-formed because the length does not match the amount of ensuing data. At this point, what happens during reading depends entirely on the application. For example, binspector will produce the following:
1 2 3 4 | |
Binspector (and any other application reading a pascal_t) needs length to derive the contents of string. Intelligent fuzzing is based on the observation that the more interesting values are the ones used to drive further reading of the file. With a well-formed binary and an associated format grammar, Binspector can produce a series of derivative files that have been strategically altered. (The fuzzing engine used to be a separate tool I called Hairbrain. Despite my love of the name, it was easier to maintain the tools as one codebase than keep them apart.)
Integral Attacks
The first attack type starts with Binspector keeping track of the atoms in the binary that were evaluated to continue analysis. Since Binspector knows the types of these atoms (that is, how they will be interpreted) it can tweak them to try and throw off file reading code. Let’s take a look at what Binspector produces with our sample file and grammar:
1 2 3 4 | |
Binspector has generated four files, each one a corruption of file.bin in a known way. It also produces an attack summary file which details what it has done:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
The file is delineated per-attack. You will notice there are two atoms Binspector decided to attack: the lengths of the two pascal_t structures. The lines prefixed by ? reveal what Binspector knows about those particular atoms that are relevant to fuzzing them. The lines prefixed by > reveal files derived from the known good file but that have been attacked. For the case of integer atoms it changes the values to all-zeroes (_z) and all-ones (_o).
You now have four files against which you can harden the file code of your pascal_t-reading application, each of which may throw it completely off the rails.
Shuffle Attacks
Many file formats or substructures within them are block-based. For example, a PNG contains a series of chunks that flesh out its contents. A PNG always starts with an IHDR chunk, and always finishes with an IEND chunk, and in the middle can be a varying number of others. For example:
1
| |
A shuffle attack is based on the observation that contiguous chunks of data may affect input code differently if they are rearranged. We know that these chunks together occupy N bytes in the file, and this is true regardless of the order they are in. Therefore we are free to shuffle them in-place, and we know the rest of the file should still hold up. For example what if we tried to open the above PNG that had been altered thusly:
1
| |
Whether or not the above reordering still constitutes a valid PNG is irrelevant. What matters is how input code will handle it. It may look enough like a PNG to begin the file input process, only to be thrown into the weeds when it is faced with an unexpected chunk.
Since we may not want to shuffle every array found in a binary, Binspector has a special keyword to enable this kind of attack. Lets modify the format grammar slightly and see what kind of fuzzing result comes out:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
In this format grammar we have consolidated first and last into a two-element array, and have suffixed the statement with the shuffle keyword. This lets Binspector know that we are interested in producing a shuffle attack on what it finds. The resulting fuzz produces the following attack summary:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
In a hex editor, it is easy to see the shuffle file’s contents have been reordered:
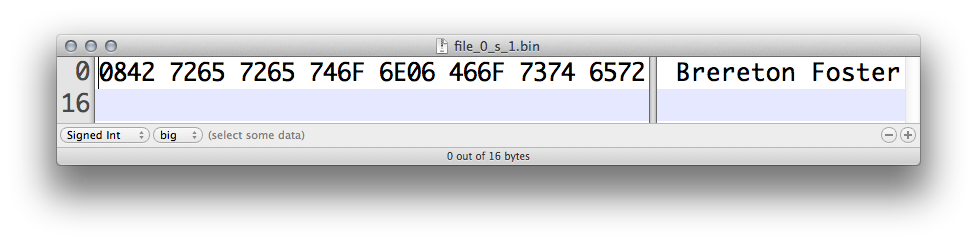
In this particular case the shuffle attack is unlikely to reveal any problems with an application’s read code. However (as is the case with PNG) it does not take much to turn an innocuous file on its head, and perhaps cause input code to nosedive in turn.
Fuzzing as a means of security testing is as much art as it is science. Many enhancements can go into Binspector’s current engine to make it more useful than it is (for example, producing files that have been attacked in several ways, not just one). Also, intelligent fuzzing itself should be augmented with more broad-spectrum tests, including more traditional fuzzing. Nevertheless, Binspector does provide a valuable subset of attacks, and makes them easily available to users.